
By David Seddon from Kraken Technologies.
Hi, I’m David, a Python developer at Kraken Technologies. I work on Kraken: a Python application which has, at last count, 27,637 modules. Yes, you read that right: nearly 28k separate Python files - not including tests. I do this along with 400 other developers worldwide, constantly merging in code. And all anyone needs to make a change - and kick start a deployment of the software that runs 17 different energy and utility companies, with many millions of customers - is one single approval from a colleague on Github.
Now you may be thinking this sounds like a recipe for chaos. Honestly, I would have said the same. But it turns out that large numbers of developers can, at least in the domain we work in, work effectively on a large Python monolith. There are lots of reasons why this is possible, many of them cultural rather than technical, but in this blog post I want to explain about how the organisation of our code helps to make this possible.
Layering our code base
If you’ve worked on a code base for any length of time, you will have felt the drift towards unpleasant complexity. Strands of logic tangle together across your application, and it becomes increasingly difficult to think about parts of it in isolation. This is what started happening to our young code base, and so we decided to adopt what is known as a ‘layered architecture’ where there are constraints about what parts of the code base can know about each other.
Layering is a well-known software architecture pattern in which components are organized, conceptually, into a stack. A component is not allowed to depend on any components higher up the stack.
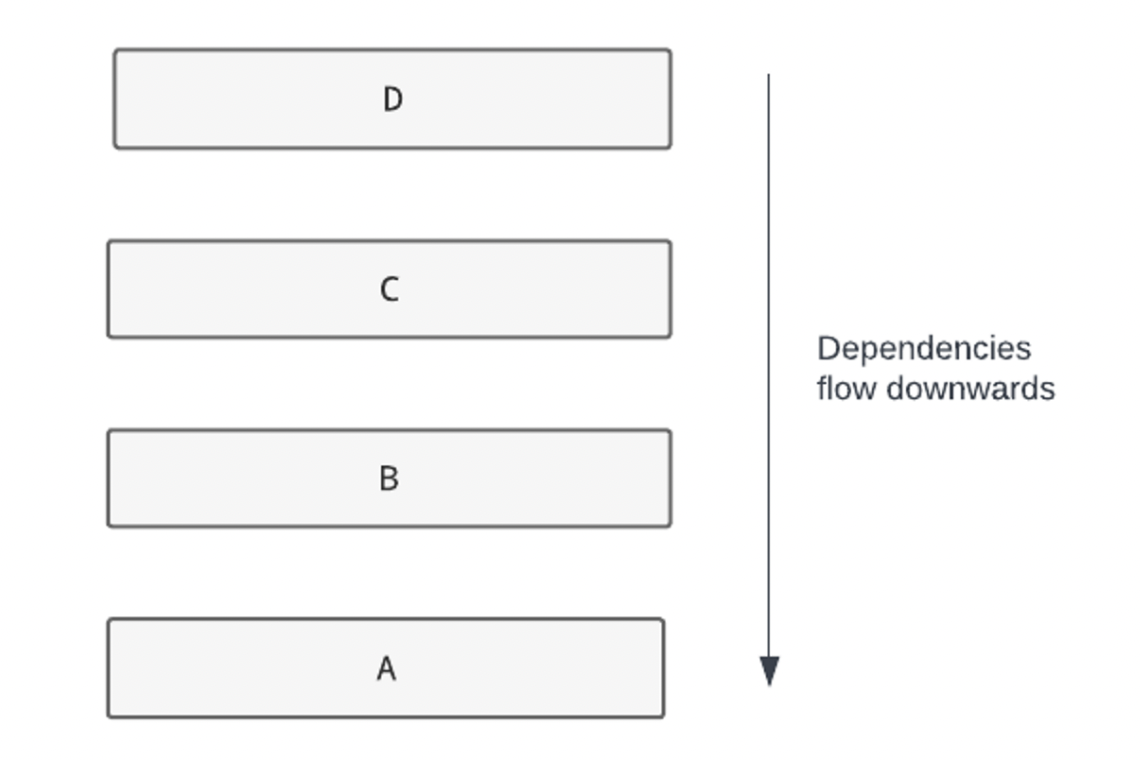
For example, in the above diagram, C would be allowed to depend on B and A, but not D.
The idea of a layered architecture is broad: it may be applied to different kinds of components. For example, you could layer several independently-deployable services; or alternatively your components could just be a set of source code files.
What constitutes a dependency is also broad. In general, if a component has direct knowledge of another component (even if purely at a conceptual level) then it depends on it. Indirect interaction (e.g. via configuration) is not usually seen as a dependency.
Layers in Python
In a Python code base, the layers are best thought of as Python modules, and dependencies as import statements.
Take the following code base:
myproject
__init__.py
payments/
__init__.py
api.py
vendor.py
products.py
shopping_cart.pyThe top-level modules and subpackages are good candidates for layers. Let’s say we decide the layers should be in this order:
shopping_cart
payments
productsOur architecture would thus forbid, for example, any of the modules within payments from importing from shopping_cart. They could, however, import from products.
Layering can also be nested, so we could choose to layer within our payments module like so:
api
vendorThere’s no single, correct way of choosing which layers exist, and in which order - that’s an act of design. But layering like this leads to a less tangled code base, making it easier to understand and change.
How we’ve layered Kraken
At the time of writing, 17 different energy and utility companies license Kraken. We call these companies clients, and run a separate instance for each. Now, one of Kraken’s main characteristics is that different instances are ‘the same, but different’. In other words, there is a lot of shared behavior, but also every client has bespoke code that defines their specific needs. This is also true at the territory level: there are commonalities between all the clients that run in Britain (they integrate with the same energy industry) that aren’t shared with, say, Octopus Energy Japan.
As Kraken grew into a multi-client platform, we evolved our layering to help with this. Broadly speaking, it now looks like this at the top level:
kraken/
__init__.py
clients/
__init__.py
oede/
oegb/
oejp/
...
territories/
__init__.py
deu/
gbr/
jpn/
...
core/The clients layer is at the top. Each client gets a subpackage inside that layer (for example, oede corresponds to Octopus Energy Germany). Below that is territories, for all the country-specific behaviour, again with territory-specific subpackages. The bottom layer is core, which contains code that is used by all clients. There is an additional rule, which is that client subpackages must be independent (i.e. not import from other clients), and the same goes for territories.
Layering Kraken like this allows us to make changes with a limited ‘blast radius’. Because the clients layer is at the top, nothing depends on it directly, making it easier to change something that relates to a particular client without accidentally affecting behavior on a different client. Likewise, changes that relate only to one territory won’t affect anything in a different one. This allows us to move quickly and independently across teams, especially when we are making changes that only affect a small number of Kraken instances.
Enforcing layering with Import Linter
When we introduced layering, we quickly found that just talking about the layering was not enough. Developers would often accidentally introduce layering violations. We needed to enforce it somehow, and we do this using Import Linter.
Import Linter is an open source tool for checking that you are following layered architectures. First, in an INI file you define a contract describing your layering - something like this
[importlinter:contract:top-level]
name = Top level layers
type = layers
layers =
kraken.clients
kraken.territories
Kraken.coreWe can also enforce the independence of the different clients and territories, using two more contracts (this time `independence` contracts)
[importlinter:contract:client-independence]
name = Client independence
type = independence
layers =
kraken.clients.oede
kraken.clients.oegb
kraken.clients.oejp
...
[importlinter:contract:territory-independence]
name = Territory independence
type = independence
layers =
kraken.territories.deu
kraken.territories.gbr
kraken.territories.jpn
...Then you can run lint-imports on the command line and it will tell you whether or not there are any imports that break our contracts. We run this in the automated checks on every pull request, so if someone introduces an illegal import, the checks will fail and they won’t be able to merge it.
These are not the only contracts. Teams can add their own layering deeper in the application: kraken.territories.jpn, for example, is itself layered. We currently have over 40 contracts in place.
Burning down technical debt
When we introduced the layered architecture, we weren’t able to adhere to it from day one. So we used a feature in Import Linter which allows you to ignore certain imports before checking the contract.
[importlinter:contract:my-layers-contract]
name = My contract
type = layers
layers =
kraken.clients
kraken.territories
kraken.core
ignore_imports =
kraken.core.customers ->
kraken.territories.gbr.customers.views
kraken.territories.jpn.payments -> kraken.utils.urls
(and so on...)We then used the number of ignored imports as a metric for tracking technical debt. This allowed us to observe whether things were improving, and at what rate.
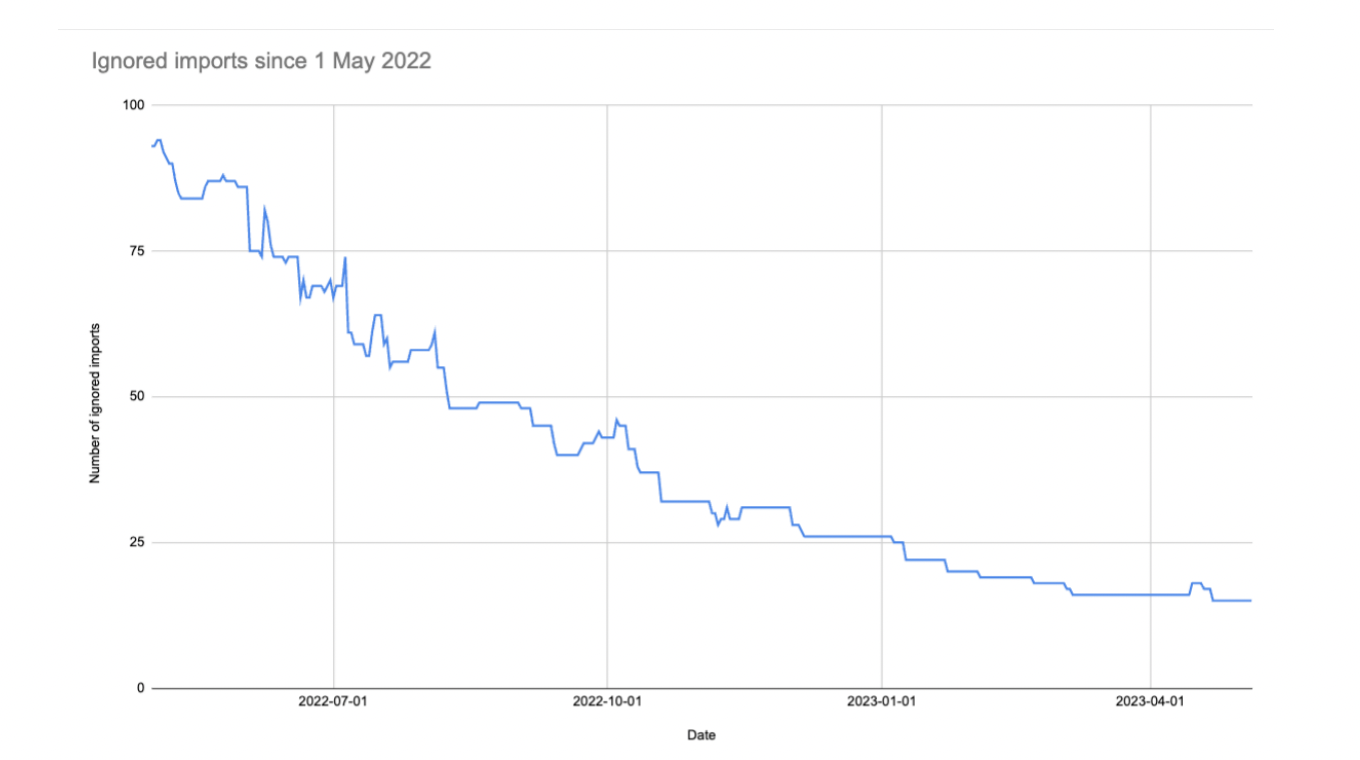
Here’s our graph of how we’ve been working through ignored imports over the last year or so. Periodically I share this to show people how we’re doing and encourage them to work towards complete adherence. We use this burndown approach for several other technical debt metrics too.
Downsides, there are always downsides
Local complexity
At some point after adopting a layered architecture, you will run into a situation where you want to break the layers. Real life is complex, there are interdependencies everywhere, and you will find yourself wanting to, say, call a function that’s in a higher layer.
Fortunately, there is always a way around this. It’s called inversion of control and it’s easy to do in Python, it just requires a mindset shift. But it does lead to an increase in ‘local’ complexity (i.e. in a little part of your code base). However, it’s a price worth paying for a simpler system overall.
Too much code in higher layers
The higher the layer, the easier the change. We deliberately made it easy to change code for specific clients or territories. Code in the core, which everything depends on, is more costly and risky to make changes to.
As a result, there has been a design pressure, brought about partly by the layering we chose, to write more client and territory-specific rather than introduce deeper, more globally useful code into the core. As a result, there is more code in the higher layers than we might ideally like. We’re still learning about how to tackle this.
We’re still not finished
Remember those ignored imports? Well, years on, we still have some! At last count, 15. Those last few imports are the stubbornest, most tangled ones of all.
It can take serious effort to retrospectively layer a code base. But the sooner you do it, the less tangling you’ll have to address.
In summary
Layering Kraken has kept our very large code base healthy and relatively easy to work with, especially considering its size. Without imposing constraints on the relationships between the tens of thousands of modules, our code base would probably have tangled into an enormous plate of spaghetti. But the large scale structure we chose - and evolved along with the business - has helped us work in large numbers on a single Python code base. It shouldn’t be possible, but it is!
If you’re working on a large Python codebase - or even a relatively small one - give layering a try. The sooner you do, the easier it will be.
Kraken Technologies LTD's is sponsor of EuroPython 2023, check them out on https://kraken.tech/